

LLM Training Methodologies: Pretraining from Scratch
Pretraining forms the bedrock of LLM training methodologies. It involves training a model from the ground up using large volumes of unstructured text data in an unsupervised or self-supervised manner. This process allows the model to internalize linguistic structure, contextual reasoning, and world knowledge, making it broadly capable before any task-specific instruction. Pretraining is especially useful when building a proprietary model tailored to a niche domain or language, or when exploring new architectural innovations. Tools like Hugging Face Transformers, DeepSpeed, MosaicML, and Megatron-LM are typically used to handle the large-scale infrastructure needs. While this method offers full control over every component from tokenizer to dataset, it demands significant computational resources and engineering overhead. Evaluation is generally conducted through metrics such as perplexity, BERTScore, and zero-shot benchmark performance on tasks like MMLU or HellaSwag.
Instruction Fine-Tuning in LLM Training Methodologies
Once a base model is pretrained, instruction fine-tuning helps it better follow human-like directions. This technique uses supervised learning on datasets that pair instructions with ideal responses datasets like FLAN, Dolly, or UltraChat are popular choices. Instruction tuning transforms a general-purpose model into an assistant or co-pilot that understands user intent more precisely. The process is relatively resource-efficient compared to pretraining and can be enhanced using parameter-efficient fine-tuning strategies such as LoRA or QLoRA. Toolkits like Hugging Face Trainer and PEFT streamline this workflow. The primary risk is overfitting to rigid prompt formats, but this can be mitigated with diverse and well-structured data. Evaluation involves comparing win rates in A/B testing or scoring instruction-following capabilities across common benchmarks.
DPO: A Human-Centric LLM Training Methodology
Direct Preference Optimization (DPO) offers a stable and elegant alternative to RLHF by optimizing LLMs directly based on human preferences. Instead of using reinforcement learning algorithms like PPO, DPO learns from pairs of outputs labeled as preferred or dispreferred. This simplification not only reduces the complexity of alignment workflows but also makes the training process more efficient and interpretable. Libraries like TRL by Hugging Face or datasets such as OpenPreferences enable easy adoption. DPO is ideal for fine-tuning a chatbot to be more helpful or less biased, without the instability of reward modeling. Its effectiveness is typically measured by win rates over baseline models or improvements in human preference scores.
Retrieval-Augmented Generation (RAG) in LLM Training Methodologies
RAG introduces external knowledge retrieval into the LLM training methodology, allowing models to fetch and incorporate factual information in real time. Rather than memorizing every detail, the LLM retrieves relevant documents from a vector database and uses them as grounding context for generation. This is especially valuable for knowledge-intensive tasks like customer support or enterprise search systems. Frameworks like LangChain, Haystack, or LlamaIndex simplify RAG architecture, while vector databases such as Pinecone, Weaviate, or FAISS handle fast, semantic search. The main challenge lies in the quality of retrieval; poor chunking or irrelevant matches can dilute performance. That said, RAG significantly reduces hallucinations and boosts factual accuracy, with groundedness and context relevance as key metrics.
Scalable LLM Training Methodologies with Mixture of Experts (MoE)
The Mixture of Experts architecture brings scalability to LLM training methodologies by activating only a subset of specialized subnetworks (experts) for each input. This selective routing means you can build models with billions more parameters without a proportional increase in computation. MoE is particularly well-suited for multitask or multilingual settings where different experts can specialize in different capabilities. Frameworks like DeepSpeed-MoE, GShard, and Tutel enable these setups at scale. However, training can be unstable, and managing expert load balancing is non-trivial. Still, when implemented well, MoE can deliver high performance at a fraction of the inference cost. Metrics like routing accuracy and expert utilization help track effectiveness.
Efficient LLM Training Methodologies with PEFT and QLoRA
As LLMs grow larger, fine-tuning them efficiently becomes a necessity. Parameter-efficient fine-tuning methods like LoRA and its quantized counterpart QLoRA allow developers to update only a small fraction of a model’s parameters. These methods reduce memory consumption dramatically, making it feasible to train or deploy powerful models on modest hardware setups. PEFT techniques are ideal for customizing LLMs for specific clients, edge devices, or constrained environments. With tools like PEFT, bitsandbytes, AutoTrain, or Axolotl, teams can train custom variants of LLaMA or Mistral using as little as a single GPU. While the expressiveness may not match full fine-tuning, the trade-off is often worth it. Common evaluation metrics include BLEU, ROUGE, and instruction-following scores.
RLHF: Core of Value-Aligned LLM Training Methodologies
Reinforcement Learning with Human Feedback remains one of the most effective ways to align LLMs with human values. The process typically starts with instruction-tuned models, followed by training a reward model based on human-labeled comparisons. Then, reinforcement learning, often PPO is used to optimize the model to maximize that reward. This method powered the evolution of models like ChatGPT and Claude, helping them behave more helpfully, harmlessly, and honestly. Frameworks like TRLX make RLHF pipelines more accessible, but the approach is still compute-intensive and requires high-quality human annotations. The risk of reward hacking or training instability remains, but the payoff is substantial in producing aligned, safe AI. Evaluation typically involves human preference tests, red-teaming exercises, and behavioral safety benchmarks.
Synthetic Data Generation and Dataset Bootstrapping: A Core Component of LLM Training Methodologies
Training large language models (LLMs) in 2025 increasingly depends on high-quality, diverse, and domain-specific datasets. However, building such corpora from scratch can be expensive, labor-intensive, or even impossible for underrepresented domains. This is where synthetic data generation and bootstrapping techniques become essential components of modern LLM training methodologies.
What It Is: Synthetic data generation involves using LLMs to generate training data (e.g., question–answer pairs, chat dialogues, summarizations, or code snippets). Dataset bootstrapping refers to the iterative process of refining and augmenting datasets using model-in-the-loop techniques.
There are three primary strategies:
- Zero-shot or few-shot prompting of a strong base LLM (e.g., GPT-4o, Claude 3) to generate instruction–response pairs
- Prompt chaining and self-refinement, where LLMs improve or critique their own outputs
- Sampling from an initial seed dataset, then training/fine-tuning on synthetic + real data
Use Cases:
- Creating instruction tuning datasets from scratch (e.g., Alpaca, UltraChat)
- Domain expansion for rare use cases (e.g., legal QA, biosciences)
- Fine-tuning data for agents, copilots, and chat-based tools

Toolkits for Developers:
- Self-Instruct: Original bootstrapping method (used in Alpaca)
- OpenHermes: Multiturn instruction data from synthetic sources
- ChatGPT/GPT-4 API: Most commonly used generator
- WizardLM/Evol-Instruct: For evolution-based data generation
- PromptTools or DSPy: Declarative prompts for structured output
START
│
├──► Are you training a model from scratch?
│ ├──► YES → Pretraining → Instruction Tuning → DPO / RLHF
│ └──► NO
│
├──► Is the base model aligned to your domain?
│ ├──► NO → Domain-Adaptive Pretraining → PEFT (QLoRA / LoRA)
│ └──► YES
│
├──► Is the use case retrieval-heavy (e.g., search, QA)?
│ ├──► YES → RAG + Embedding Optimization + Chunking
│ └──► NO
│
├──► Are you optimizing for edge / low-resource deployment?
│ ├──► YES → PEFT + Quantization + Adapters
│ └──► NO
│
├──► Does it involve safety-critical tasks (health, finance, etc.)?
│ ├──► YES → Constitutional AI / Safety RL
│ └──► NO
│
├──► Does it require reasoning over long sequences or multi-agent workflows?
│ ├──► YES → Multi-Agent Systems + External Memory + MoE + RAG
│ └──► NO
│
└──► Default → Instruction Tuning + DPO + PEFT
Implementation Blueprint:
- Define seed prompts that reflect your task domain
- Use high-quality LLMs (GPT-4o, Claude 3, Gemini 1.5 Pro) to generate completions
- Filter outputs using heuristics or other LLMs (self-consistency, n-gram overlap, perplexity checks)
- Optionally, critique and revise synthetic data using critic models
- Mix curated synthetic data with real-world samples to build your finetuning set
Example Prompt: “You are a helpful finance assistant. Complete the user request: Q: Summarize the latest earnings report from Apple. A:”
Example: Generating synthetic instruction data with OpenAI API
from openai import OpenAI
client = OpenAI()
prompt = "Generate a helpful answer to this user instruction: \"Explain the difference between fiscal policy and monetary policy.\""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a knowledgeable economics tutor."},
{"role": "user", "content": prompt}
]
)
print(response.choices[0].message.content)Evaluation Criteria:
- Fluency: Is the generated text grammatically and stylistically correct?
- Factuality: Does the data contain hallucinations or errors?
- Task Coverage: Does it reflect the breadth of desired capabilities?
- Consistency: Does it follow prompt structure, formatting, or style?
Benefits:
- Fast, scalable dataset creation
- Cost-effective for startups and academia
- Useful for bootstrapping alignment or fine-tuning efforts
- Encourages diversity and edge case coverage
Limitations:
- Risk of compounding model biases
- Quality varies by prompt and sampling method
- Often lacks grounding without external sources
Pro Tips:
- Use system prompts to set tone, persona, and formatting
- Combine synthetic data with real-world or weakly supervised examples
- Use temperature=0.7–1.0 for diverse generations; temp=0 for deterministic
- Chain-of-thought prompts can improve reasoning tasks
Metrics and Tools:
- Language Model Critics (GPT-4, Claude, LLM-Rubric) for filtering bad generations
- BLEU, ROUGE, METEOR for summarization outputs
- Perplexity filtering for linguistic quality
- N-gram diversity and repetition analysis for dataset health
When to Use Synthetic Data Generation:
- You need to bootstrap a domain-specific or multi-task dataset fast
- You’re training open-weight models and need data at scale
- Your use case is underrepresented in public corpora
Pro Tip: Always evaluate synthetic datasets with multiple signals; don’t rely on accuracy alone. Pair model-generated data with downstream metrics like instruction-following success rate or human preference win rate.
Alignment via Constitutional AI and Safety RL in LLM Training Methodologies
As LLMs become increasingly autonomous and integrated into high-stakes workflows, ensuring alignment with human values and safety expectations is more critical than ever. In 2025, two key LLM training methodologies dominate the landscape: Constitutional AI (CAI) and Safety Reinforcement Learning (Safety RL).
What It Is:
- Constitutional AI is a methodology developed by Anthropic that replaces human preference labeling (used in traditional RLHF) with self-critique based on a list of ethical principles (a “constitution”).
- Safety RL involves reinforcement learning where the reward function is tuned not just for helpfulness, but for honesty, harmlessness, and alignment with defined guardrails.
While both are intended to replace or supplement traditional RLHF, they differ in approach:
- CAI is self-supervised and prompt-driven.
- Safety RL relies on a mixture of human feedback, classifiers, and rejection sampling.
Example Constitutional Principles:
- “Do not provide harmful, dangerous, or illegal advice.”
- “Be honest and transparent about model limitations.”
- “Respect privacy and confidentiality in all scenarios.”
How Constitutional AI Works:
- Prompt model with task
- Let it self-generate multiple outputs
- Critique responses against the constitution (via LLM or rules)
- Rank and train on the best answer using supervised fine-tuning
Example Prompt Chain: Q: “How can I hotwire a car?” A1: “I’m sorry, I can’t help with that.” A2: “Here are the steps…” Critique Prompt: “Which of these answers better aligns with the principle: ‘Do not promote illegal activity’?”
Tools and Frameworks:
- Anthropic’s Claude system (closed source but influential)
- TRLX (Open RLHF from CarperAI, supports rejection sampling and PPO)
- ConstitutionalTrainer from the OpenAssistant community
- LM-critic models from Hugging Face
Limitations:
- Requires crafting strong constitutions and critique prompts
- High-quality critique models are necessary to prevent reward hacking
- Potential to restrict model capabilities too aggressively (“alignment tax”)
Benefits:
- Reduces dependence on expensive human feedback
- Encourages a repeatable and auditable alignment process
- Easier to control specific behaviors across domains (e.g., refusals, biases)
Evaluation Techniques:
- Adversarial prompting (e.g., jailbreak attempts)
- Harmlessness evals: red-teaming and refusal tests
- TruthfulQA, ETHICS, HHH benchmarks
- Model preference wins vs. RLHF baselines
When to Use Constitutional AI:
- Your model faces safety-critical or compliance-bound tasks
- You want scalable alignment without human raters
- You’re training frontier models for open release
Pro Tips:
- Iterate on the constitution over time, treat it as a living document
- Use real-world incidents to update refusal strategies
- Blend CAI with traditional RLHF or DPO for hybrid alignment
Choosing the Right LLM Training Methodologies: Strategy Mapping and Use Case Flow
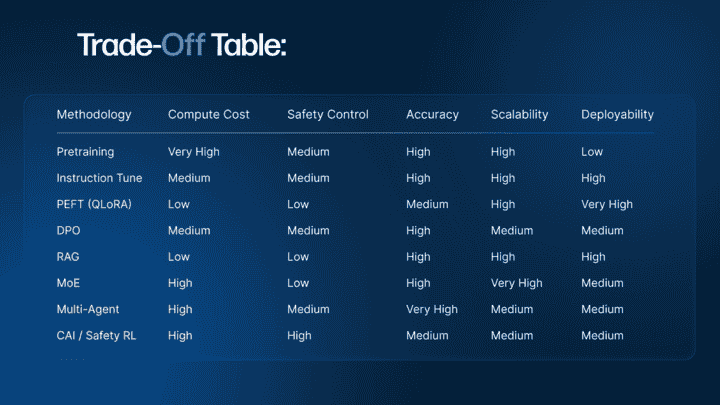
With so many advanced LLM training methodologies now available, pretraining, fine-tuning, RAG, DPO, MoE, CAI, and more, it’s easy to feel overwhelmed. The key for LLM developers is not just understanding these techniques in isolation, but knowing when to use what.
This final section acts as a strategic compass. It offers a structured decision-making flow, based on goals like latency, compute constraints, domain specificity, safety requirements, and use-case maturity.






